 Why InfiSight
Why InfiSight AI at InfiSight
AI at InfiSight 门店智能督查
门店智能督查 AI 员工培训
AI 员工培训
 24h AI 门店管家
24h AI 门店管家 空间客流应用
空间客流应用 公司介绍
公司介绍 智睿博客
智睿博客
 AI at InfiSight
AI at InfiSight AI 员工培训
AI 员工培训Mimo Vision 算法模型全面升级,与你一起拓展智能边界
两天前,我们分享了 AI 算法是如何通过学习最终形成管理连锁店铺的能力,后来算法团队表示图像识别技术有点过时了,现在视觉大模型才是这方面的翘楚。
该大模型凭借其庞大的规模和深度学习能力,正在重新定义我们对视觉信息处理的认知。它不仅能识别图像中的对象,还能理解场景、情感,甚至是图像背后的故事。
这也意味着我们现在可以利用这些先进的模型来执行更复杂的任务,比如实现过去因静态图片无法定义规则而不能满足的客户需求,现在通过大模型能在 7 天内实现。2024 年 11 月,InfiSight 凭借大模型 Mimo Vision 的引入,对复杂业务工作流进行编排激发大模型能力,成功实现上百个落地场景
01 全面升级的算法模型
Mimo Vision 作为智睿视界尖端智慧商业场景 AI 点检工具,其核心动力源自视觉大模型 Mimo。依托 InfiSight 在连锁零售领域的深厚积淀,Mimo 视觉大模型汇聚了对智慧连锁商业的深刻洞察以及数百种门店管理算法的精准需求和数据。
这些积累不仅极大提升了门店 AI 点检的准确性和细节丰富度,还能迅速响应连锁总部的多样化算法需求。Mimo 的自我学习能力更是其亮点之一,它能够迅速适应多变的商业场景,显著增强算法的泛化能力(Generalization)。
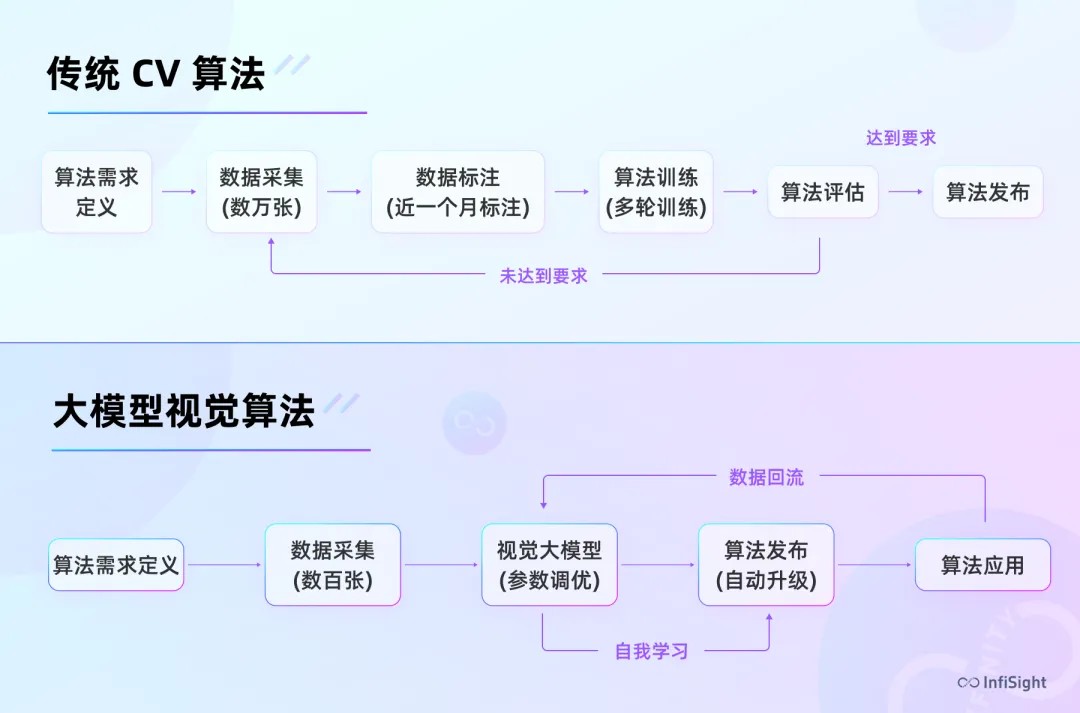
02 效率和成本的变化
• 训练时长从 60 天变成 7天
过去,要完成一个算法训练,首先在数据采集上就是数十万张图片的级别,接着还需要经过数据标注、模型训练、模型评估、模型优化共计 5 个流程,花费大约 60 天的时间。而视觉大模型过滤掉了繁杂的图片采集工作,只要指定 1000 张左右的参考图片花 7 天时间就能训练出来,效率提升 88%+,这是一个令人震惊的数字。
• 1 个人完成 5 个人的工作
传统的算法训练,人力是必不可少的资源。仅一个算法,就需要至少 1 个算法工程师 + 2 个数据工程师 + 2 个数据标注员这样 5 个角色分工完成算法训练流程上的所有工作。现在只要 1 个算法工程师就能完成以上所有工作,且准确率达到甚至高于传统 CV 算法的场景准确率水平,人力成本直降 80%。

• 快速实现客户的多样化需求
在和不同的客户一次次沟通需求的过程中,有很多特定需求能用自然语言描述出来,但在图像识别技术的语境中难以用规则去定义,于是几乎无法实现这些需求,但视觉大模型可以。它不仅能够实现复杂需求,还能弥补图像识别技术训练出的算法泛化性差等缺点。
• 更先进的技术,并不会增加使用者的成本
看到这里的你也许会想,这么先进的技术,一定很贵。答案是否。使用成本不会增加的原因是,协创数据技术股份有限公司(股票代码300857)于今年 10 月采购了 AI GPU 服务器,该服务器将专门用于搭建一个具备万卡级算力的大型服务集群,强化了协创数据在高速增长的人工智能应用中的地位。
AI GPU 服务器以其高效的计算能力和优秀的数据并行处理能力著称,能够有效支持大规模数据处理和深度学习任务,尤其适用于大型模型的训练与推理。这种强大的计算资源不仅能够满足当前市场对 AI 算力需求的迫切性,还为未来的技术突破奠定了基础。InfiSight 智睿视界作为协创数据的 AI 事业部,得益于这种高性能服务器,产生了显著的边际效应,从而使得成本保持在合理范围内。
03 面对复杂需求,一周内提供测试版本
视觉大模型远超于传统小模型的视频、图片理解能力,很好地泛化到线下零售连锁门店日常的管理任务上。系统通过 Mimo Vision 自主理解检查标准文本和示例图片,模拟了管理者对门店的日常监管流程,对监控画面中的员工、门店运营和消费者数据进行细致的分析和深度推理,在提高门店经营效率和收入的同时,也帮助一线员工在工作上获得成功。
过去,面对客户提出的非行业通用算法需求,我们也许会说「等我采集数据训练一下」,这一等就是两个月。但现在,我们有信心回答:现在没有,但过几天就会有。
• 迎宾行为
比如,本月初,我们遇到了一个连锁餐饮品牌的客户需求,他们想要检测员工的「迎宾行为」。听起来可能有点抽象,因为「迎宾行为」并不是那么容易用图像识别技术直接定义。但我们的视觉语言大模型已经在海量数据中接受了训练,它能够在语言和视觉之间建立联系,也就是在语义层面上将两者对齐。这意味着,我们可以通过简单的语言提示,也就是给模型一个指令,让它去判断图片中的人是否正在进行迎宾行为。

我们要做的是,在大模型中上传一张图片,并给出提示词,让大模型识别图片中是否存在以下行为:
“一位微笑并鞠躬迎接客人的人。”
“一个人用手势示意客人进入,并面带微笑。”
“服务人员打开门,用热情的动作欢迎客人进入。”
“服务人员在门口与顾客交谈”
“服务人员引导顾客入座”
“服务人员在维持等候区秩序”
……
这样,即使「迎宾行为」这个概念比较模糊,我们的模型也能够理解并识别出来。经过大约 7 天的微调训练,我们就为客户提供了「迎宾行为」算法的测试版。
• 肢体冲突
员工与顾客、顾客与顾客在店内产生肢体冲突的事件一旦被爆出,对品牌的伤害是非常持久的,所以这类事件在 PR 人眼中是「严禁发生」事件。
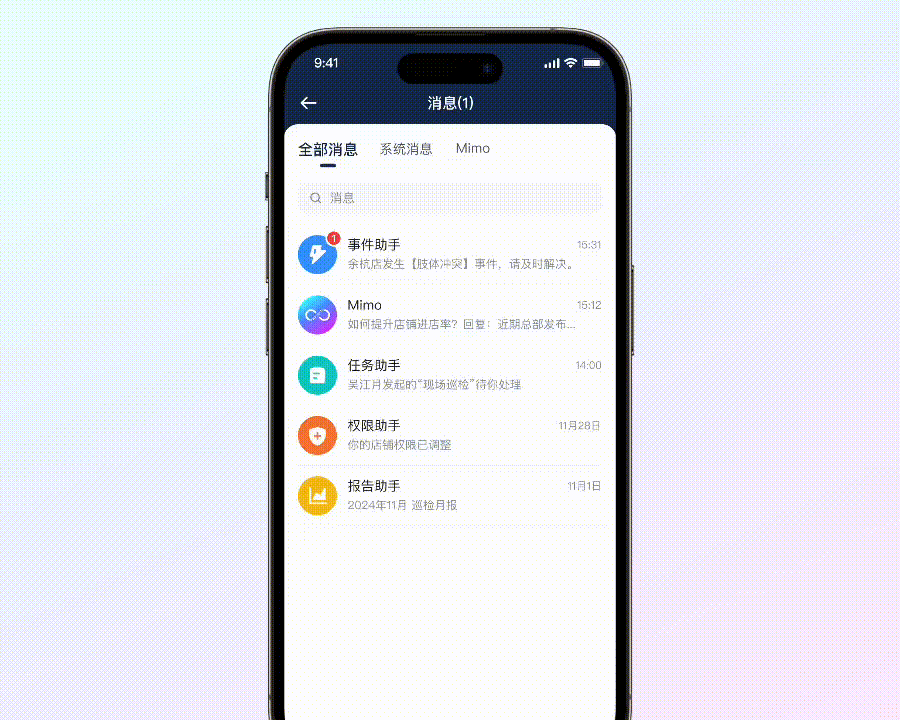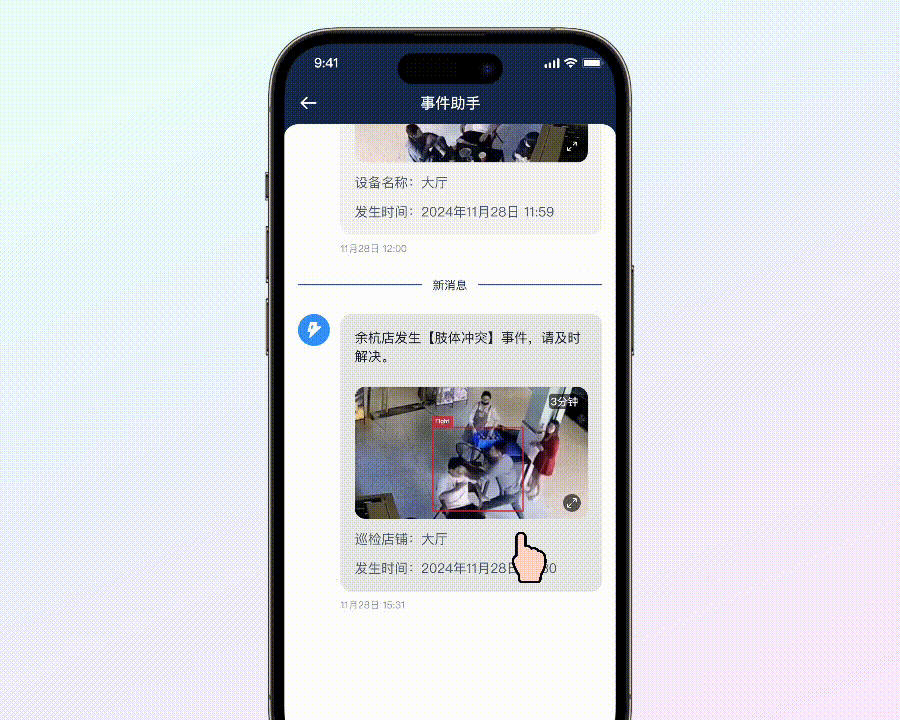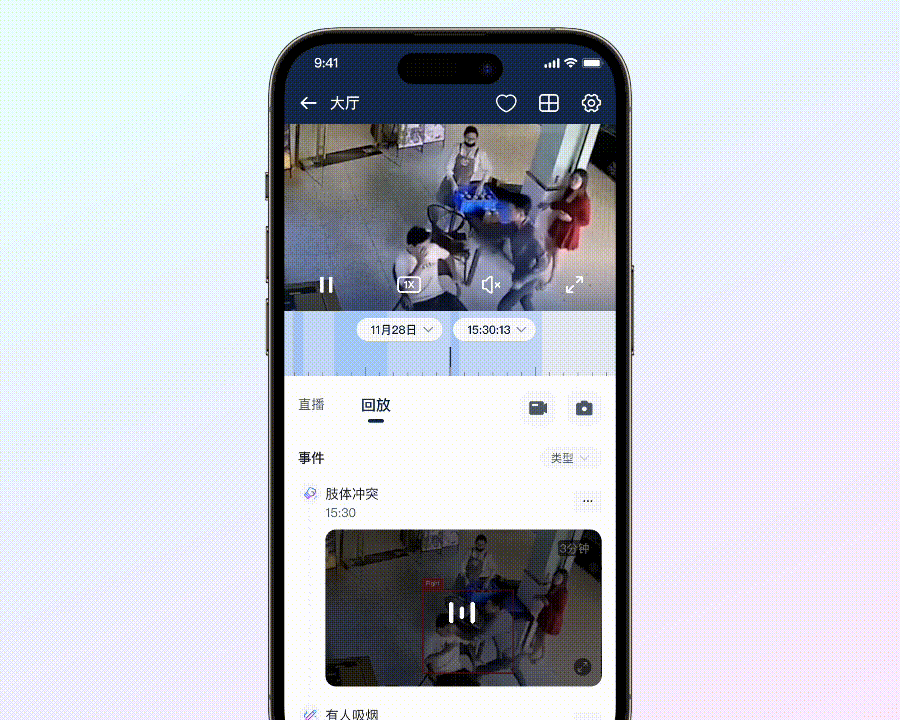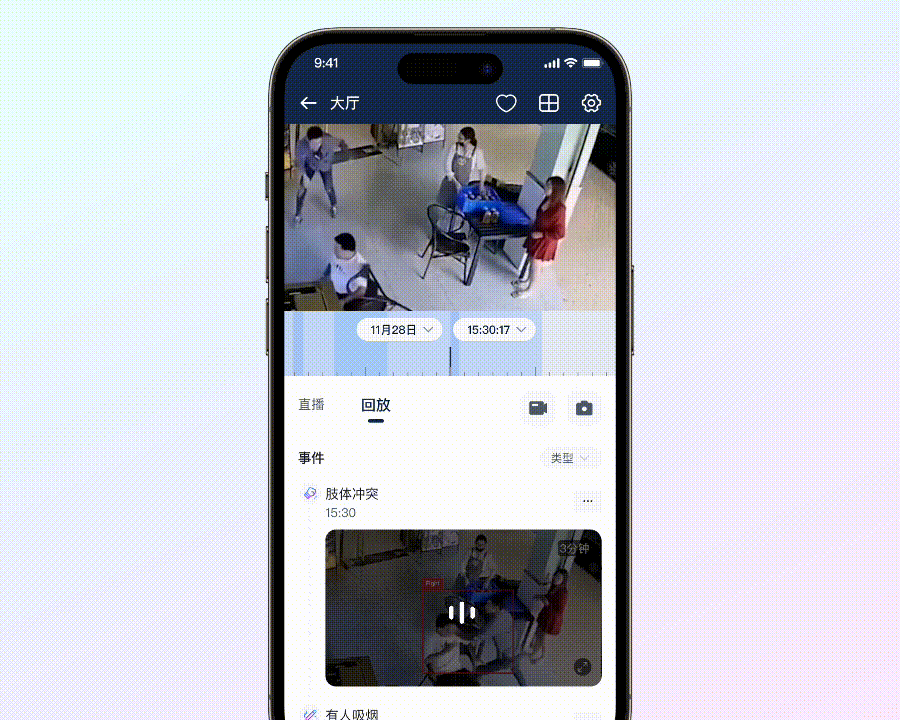
以往,要让 AI 识别出「肢体冲突」这样的行为,我们需要用成千上万甚至数十万级别的视频数据来训练它,让它学习理解是什么构成了肢体冲突。即便如此,经过这样大规模的训练,准确率也只能达到大约 80%。然而,现在有了大模型,情况就完全不同了。仅仅通过一张图片就能准确识别出打架行为,而且准确率能够达到惊人的 99%。这意味着我们不再需要依赖海量、丰富的数据集来训练 AI,大大减少了资源消耗和时间成本。
接下来,InfiSight 会带着大模型帮助客户解决更有挑战的复杂门店管理场景。我们会一起努力,让门店经营与管理这件事变得更加轻松、高效。

添加小助手
推荐阅读
-
 InfiSight 时空行为分析引擎正式发布,让 AI 真正理解现场的每一个连续行为
InfiSight 时空行为分析引擎正式发布,让 AI 真正理解现场的每一个连续行为2026.05.14
-
 明厨亮灶新规落地,餐饮商家如何打赢长效合规打赢保卫战?
明厨亮灶新规落地,餐饮商家如何打赢长效合规打赢保卫战?2026.04.14
-
 24h AI 门店管家:终结周期巡店的管理盲区
24h AI 门店管家:终结周期巡店的管理盲区2026.03.26
